Why this matters: You cannot improve what you cannot measure. Understanding LLM reliability ensures AI systems are safe, factual, and useful before they reach production.
The Non-Determinism Experiment
Imagine writing a standard software test: assert 2 + 2 == 4. It passes every time because code is deterministic. Now, let's test a Large Language Model.
Activity: Click "Run Prompt" to ask an LLM: "Explain gravity in one sentence." Watch what happens when you run the exact same prompt twice.
Moving Beyond Exact Match
Traditional software testing relies on exact, predictable outputs. Generative AI shatters this paradigm. Because LLMs sample from probability distributions, their outputs vary.
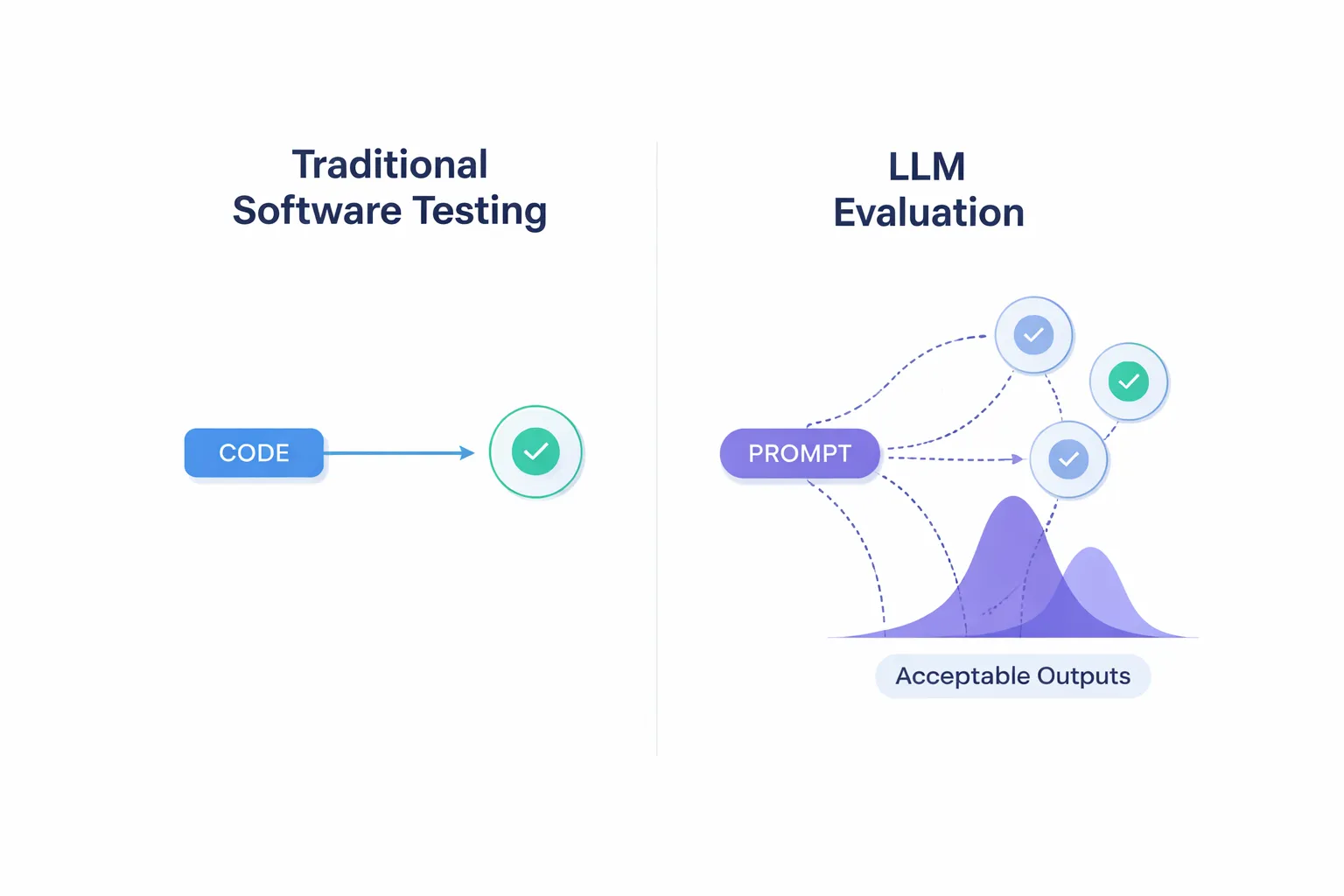
Instead of checking if output == expected_string, evaluating AI requires measuring distributions of acceptable outputs. We must shift to "fuzzy metrics" like semantic similarity, relevance, and factual consistency. Frameworks like RAGAS help measure these non-exact dimensions systematically.
Probabilistic Outputs
A user submits the same prompt to your application three times. They receive three answers that use slightly different wording but contain the exact same factual information. Is this a system failure?
Human Evaluation vs. LLM-as-a-Judge
How do we score these fuzzy, probabilistic outputs at scale? We use two primary methods in tandem. Click the cards below to reveal their strengths and weaknesses.
Human Evaluation
Experts reviewing outputs manually.
Click to flip ↺Pros: Excellent for nuanced, subjective topics. Creates the ultimate "golden dataset" for ground truth.
Cons: Highly expensive and too slow to run during daily developer workflows.
LLM-as-a-Judge
Using an AI model to grade another AI model.
Click to flip ↺Pros: Instant, scalable, and perfect for rapid regression testing across thousands of prompts.
Cons: Subject to its own biases. Requires a robust rubric to evaluate effectively.
Measuring the Immeasurable
When using "LLM-as-a-Judge", we must instruct the AI what to look for. Frameworks like RAGAS break down response quality into distinct, measurable metrics. Click the sections to expand.
Measures if the LLM's answer is derived only from the provided source context. If the LLM brings in outside knowledge or invents facts, it scores low on faithfulness.
Evaluates how directly the answer addresses the user's actual prompt. An answer can be highly factual, but completely irrelevant to what the user asked.
Aimed at the retrieval system: did it pull the most highly relevant documents to the top of the context window to feed the LLM?
Guardrails & Feedback Loops
Even with great evaluation, LLMs will occasionally hallucinate or fail. Real-world systems protect users by implementing active guardrails.
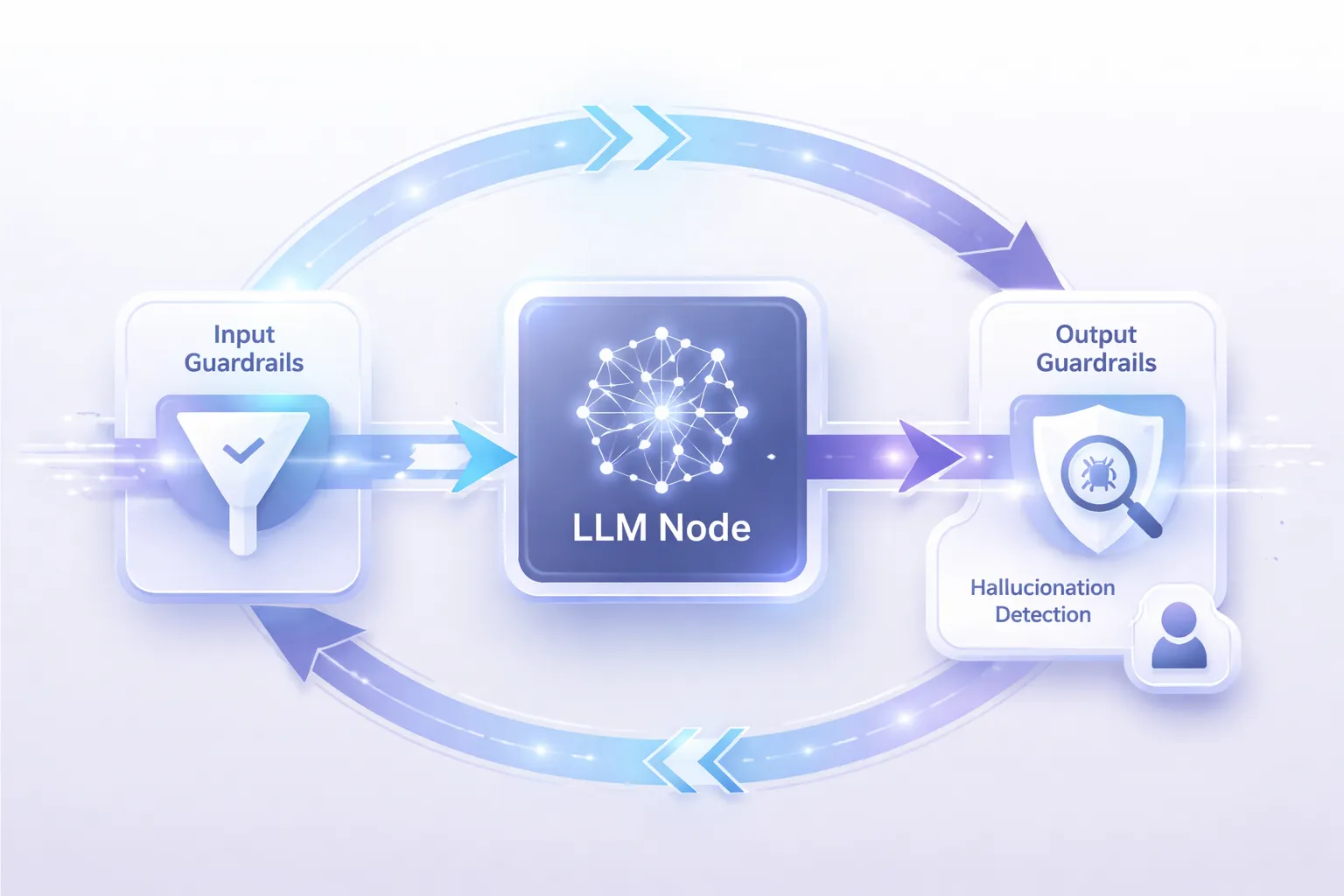
Input Guardrails: Block malicious prompts or PII before the LLM even sees them.
Output Guardrails: Analyze the LLM's response before it reaches the user. If hallucination detection flags the output as ungrounded, the system suppresses it and triggers a retry.
Scalable Testing
Which scenario is the BEST use case for an automated "LLM-as-a-Judge" pipeline rather than a human evaluation team?
Key Takeaways
- Probabilistic Nature: LLMs do not produce identical outputs. Evaluation requires measuring semantic intent, not exact string matching.
- Dual Approaches: Human evaluation provides high-quality ground truth, while LLM-as-a-Judge allows rapid scaling and automated regression testing.
- Core Metrics: Focus on metrics like Faithfulness and Answer Relevance to ensure quality in RAG applications.
- Guardrails: Implement input and output guardrails to catch failures and hallucinations before they impact end-users.
You're now ready for the final assessment. Good luck!
Final Assessment
This assessment contains 5 questions designed to test your understanding of evaluation and reliability in LLM systems.
Testing Paradigms
Why does traditional deterministic software testing (e.g., asserting identical string matches) generally fail for generative AI systems?
Evaluation Choices
When should an engineering team prioritize "LLM-as-a-Judge" automated metrics over human evaluation?
System Guardrails
In a robust generative AI pipeline, where is the most critical placement for hallucination detection to ensure user safety?
Human Evaluation Limitations
What is the main limitation of using human experts to evaluate LLM outputs?
Quality Metrics
Which of the following metrics best evaluates whether an LLM's response contains only facts present in the provided source document?